谷歌CEO罕见承认落后了!Gemini 3.5 Pro被曝难产
谷歌CEO罕见承认落后了!Gemini 3.5 Pro被曝难产据最新独家爆料,谷歌目前正在紧锣密鼓地对即将发布的重磅大语言模型Gemini 3.5 Pro进行高强度的激进迭代,在正式揭晓之前,内部预计还会测试更多的版本。
来自主题: AI资讯
9133 点击 2026-06-21 10:36
 搜索
搜索
据最新独家爆料,谷歌目前正在紧锣密鼓地对即将发布的重磅大语言模型Gemini 3.5 Pro进行高强度的激进迭代,在正式揭晓之前,内部预计还会测试更多的版本。

最近几天,一个 3B 的小模型在 X 上火了,因为在一些难度可验证的推理任务上(比如编程),它进入了 Gemini 3 Pro、GPT-5 high、Claude Opus 4.5、GLM-5、Kimi K2.5 等前沿模型的性能区间,而它的体积远小于这些模型。
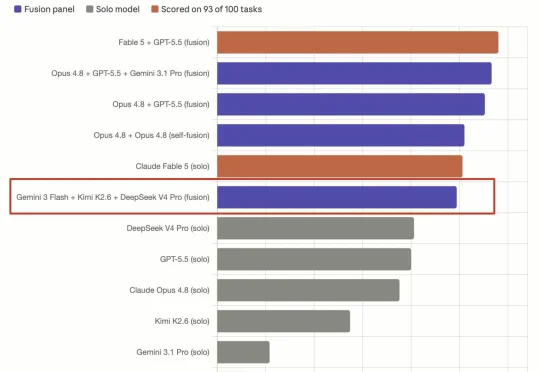
最新测试显示,模型抱团后实力明显升级:Opus 4.8+GPT-5.5>Fable 5;Kimi K2.6+ DeepSeek V4 Pro+Gemini 3 Flash=Fable 5。能力追上了,开销还减半。根据官方定价,相比Fable 5,Kimi K2.6+ DeepSeek V4 Pro+Gemini 3 Flash这套平价阵容,成本降幅接近80%。

刚刚,Google 甩出了 Gemini 3.5 Live Translate。这是它最新的语音对语音翻译模型,一句话概括:把「等你说完再翻」的老规矩,直接掀了。Google DeepMind 首席科学家 Jeff Dean 亲自发帖官宣,字里行间透着一股「二十年磨一剑」的底气:

2026 年初,各大 AI 厂商在上下文窗口长度上展开激烈角逐。Google 的 Gemini 3 Pro 已支持 100 万级 token 上下文,Meta 的 Llama 4 Scout 更宣称可处理 1000 万 token。GPT-5 系列也在快速推进长上下文能力。

“我们有点处在自己的科技泡沫里。”

他叫Yi Tay,是Google DeepMind的研究科学家。去年带着Gemini Deep Think,拿下了IMO国际数学奥林匹克金牌,今年2月Gemini 3 Deep Think的发布,他也是核心贡献者。
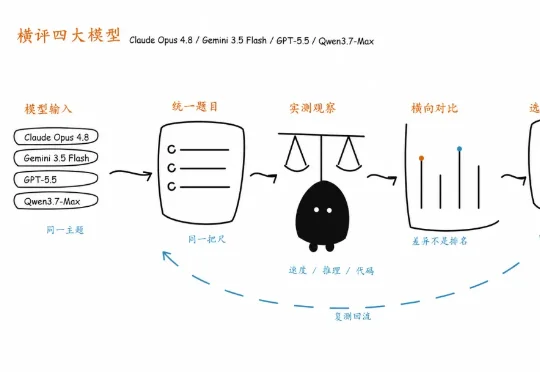
普通人看排行榜估计越看越疑惑,写文章该用哪个?数据分析该用哪个?写代码、审 PR、拆任务又该用哪个?我挑了四款最近讨论度很高的模型:Claude Opus 4.8、Gemini 3.5 Flash、GPT-5.5、Qwen3.7-Max,做一次横评,看看它们在真实任务里的交付表现。

Anthropic最强通用模型Claude Opus 4.8正式发布,新模型基准测试全面超越Gemini 3.1 Pro、Opus 4.7,仅一项逊色于GPT-5.5,但其标准模式价格不变,快速模式价格仅为Opus 4.7的1/3。与此同时,Anthropic还官宣一笔650亿美元(约合人民币4406.94亿元)H轮巨额融资,投后估值冲上9650亿美元(约合人民币6.54万亿元)

超越 GPT-5.5、Gemini 3.5 Flash、DeepSeek V4 Pro,阿里的最新旗舰模型 Qwen3.7 Max 在编程竞技榜拿下第二名,仅次于 Claude Opus 4.7。除了真实场景的用户选择,在传统的大模型固定评测榜单上,像是终端能力 Terminal Bench、编程能力 SWE Bench 等,Qwen3.7 Max 的表现也是拿下了国产模型的冠军。